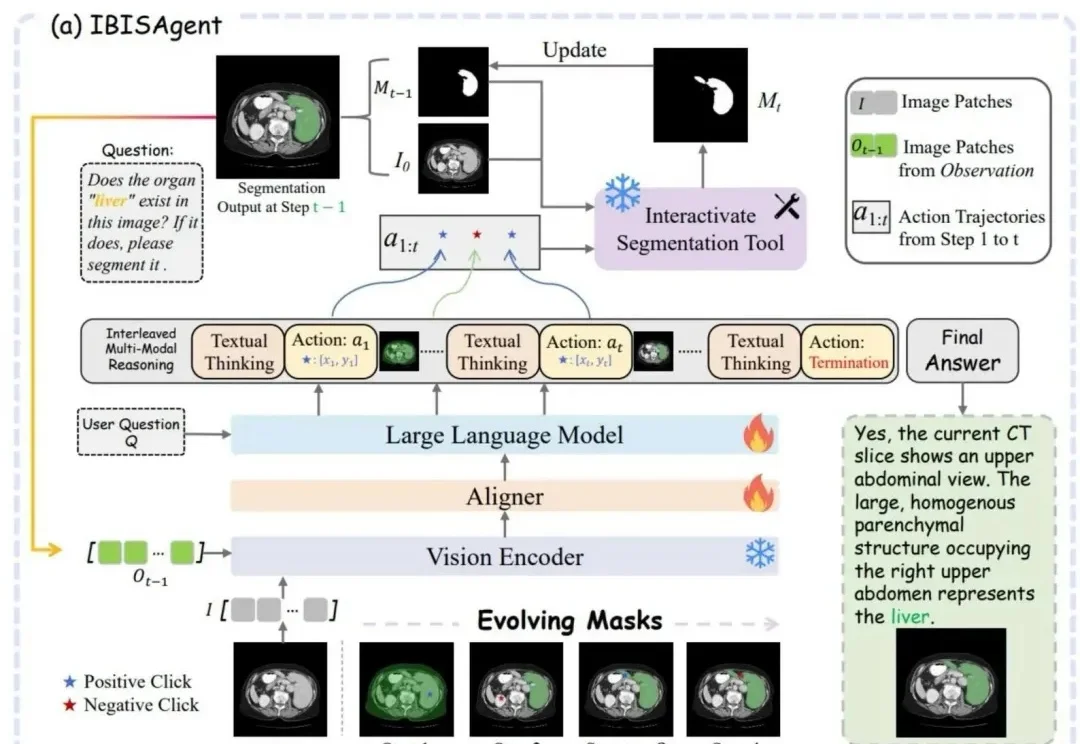
国产多模态Agent拿下医学分割SOTA!不用改模型、不加token | 浙大&上海AI Lab
国产多模态Agent拿下医学分割SOTA!不用改模型、不加token | 浙大&上海AI Lab这个生物医学视觉推理框架,被CVPR 2026接收了!
来自主题: AI技术研报
6987 点击 2026-04-22 09:11
 搜索
搜索
这个生物医学视觉推理框架,被CVPR 2026接收了!
由Liu Fayao(刘发耀,新加坡A*STAR研究科学家),Ye Deheng(叶德珩,前腾讯AI合伙人&首席专家)和Chen Tianrun(陈天润,魔芯科技创始人)带领的研究团队提出了Claw AI Lab。

近期,大厂的AI实验室正迎来一场深度结构性调整。

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。

今天,机器之心获悉,腾讯 TEG 技术工程事业群组织架构发生了部分调整,AI Lab 被撤销,蒋杰不再担任 AI Lab 主任,但其他管理职责不变。此次调整过后,原 AI Lab 部分人员调整至混元团队向姚顺雨汇报。产学研合作中心保留。多模态部负责人向 TEG 总裁卢山汇报。

让AI像Kaggle顶尖选手一样设计算法,需要几步?
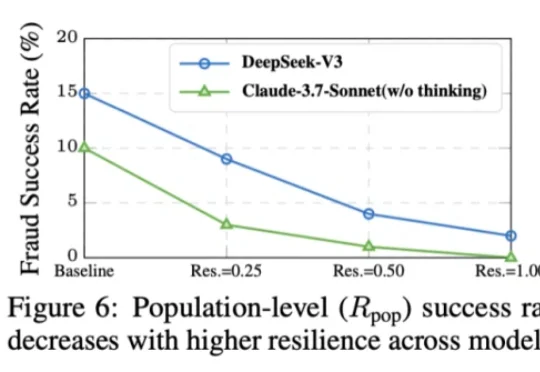
本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
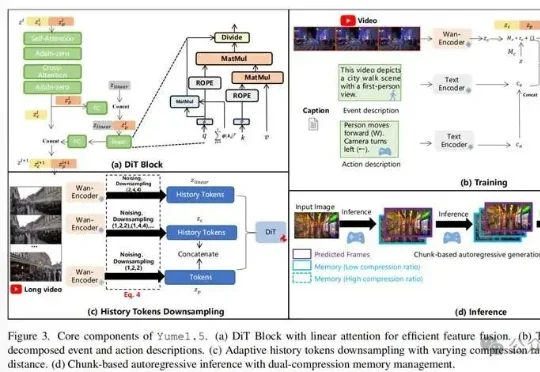
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。

组织调整后的模型答卷,将对腾讯至关重要。《智能涌现》从多名独立信源处获悉,近日,出于个人发展原因,原腾讯 AI Lab副主任俞栋将从腾讯离职。截至发稿前,腾讯官方暂未回复。